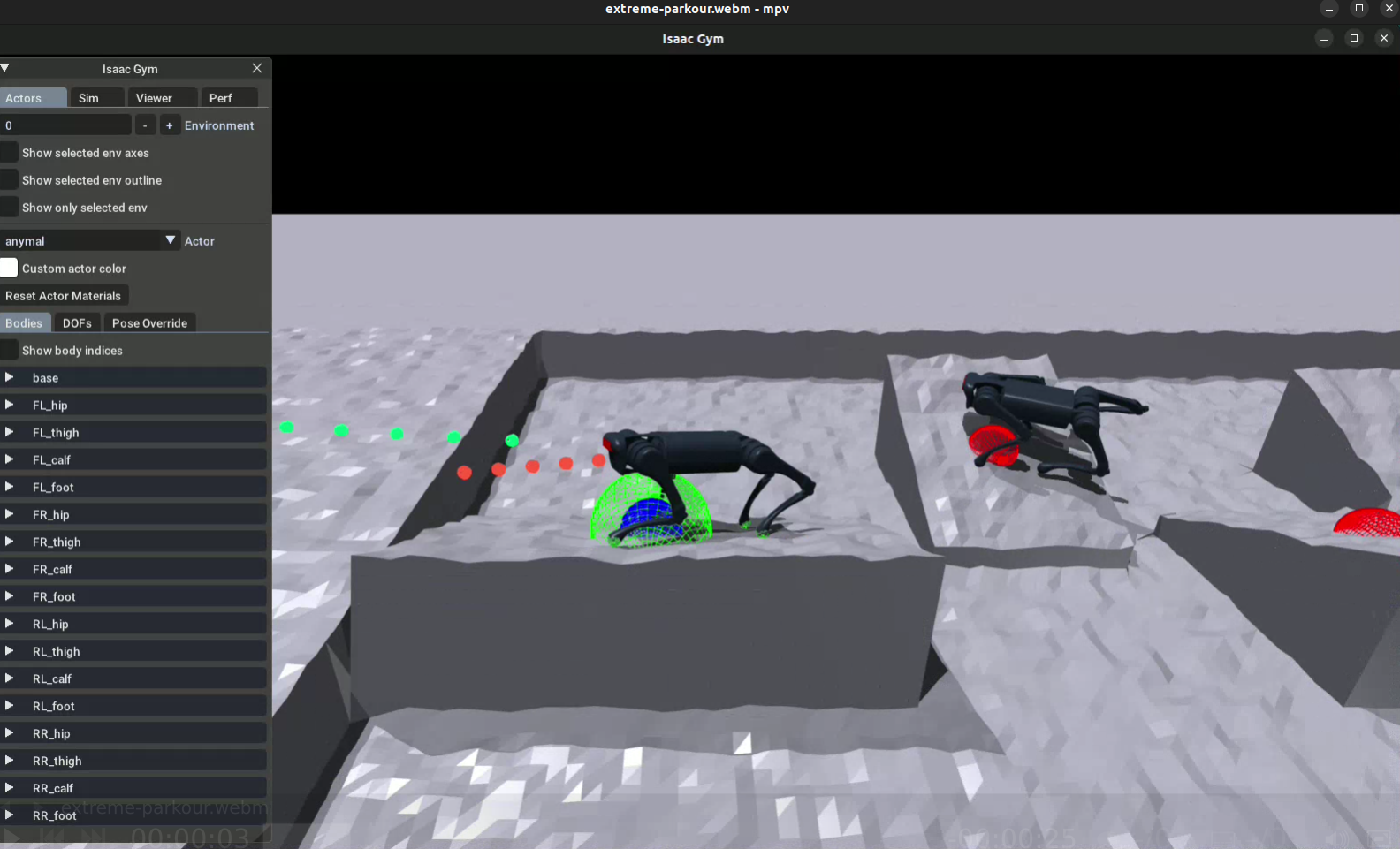
Isaac GYM 기반 Extreme Parkour with Legged Robots
Extreme-parkour
- https://github.com/chengxuxin/extreme-parkour 테스트 진행 (완료)
- conda activate parkour (가상환경)
- python train.py --exptid xxx-xx-WHATEVER --device cuda:0 (학습코드)
- python play.py --exptid xxx-xx (실행 코드)
- 비교적 잘 올라가는 모습을 보임
Extreme Parkour with Legged Robots 논문 - https://arxiv.org/pdf/2309.14341
1. Introduction
- 파쿠르는 인간이 장애물을 빠르고 역동적으로 넘다드는 운동
- 로봇에게 파쿠르 기술을 구현하는 것은 sw & hw 양쪽에서 매우 큰 도전 과제
- 정확한 인지 (perception)
- 정확한 제어 (control)
- 둘의 긴밀한 결합 (tightly coupled) -> 적절한 타이밍에 정확한 움직임을 실행해야만 성공적으로 장애물을 넘을 수 있음
- 기존 접근 방법은 장애물 배치, 크기, 종류를 사전에 정확히 측정한 뒤, 최적화를 통해 각 시간 단계마다 정확한 제어 명령을 생성
- 현실 세계에서는 불가능
- 인간은 감각 능력이 극적으로 향상되는 것이 아니라, 불완전한 감각과 근육을 오랜 시간 시행 착오를 걸쳐 최적의 활용법을 익힘
- 저비용 로봇에서도 비슷한 방식으로 파쿠르 학습이 가능할 것이다 -> 가설
- 자유롭게 방향 전환이 힘듬 / 다양한 기술을 하나의 정책으로 통합시켜야함
- end-to-end 강화학습을 통해 단일 신경망을 시뮬레이션에서 RL(Reinforce Learning으로 학습 진행)
- 카메라 픽셀 입력 -> 모터 명령 출력
- 핵심 기법 제시
- Dual Distillation Method : previleged heading direction 제공 상태로 훈련 -> 자기 스스로 방향을 예측하도록 정책을 융합
- Inner-product Reward Design Principle : 로봇 본체의 일반적인 이동을 핛브하기 위해 효과적인 보상 설계법을 제안
- automatic Terrain Curriculum : RL 훈련 중, exploration problem을 해결하기 위해 자동 난이도 적용
2. Related Work
- 기존 보행 제어 방식은 모델 기반 제어 + elevation map을 활용
- 변형 가능한 지형(deformable material)등 물리적 특성이 크게 변하는 상황에서 generalize struggle 할 수 있음
- elevation map 생성에 복잡한 센서가 필요하고, 맵 생성 오류(artifacts)가 발생하면 제어 성능 저하로 이어짐
- elevation map을 완전히 생략하고, 카메라 기반 비전 정보를 직접사용하여 robust perceptive walking을 구현한 사례
- 로봇 파쿠르 연구
- 동물과 인간은 생후 1년 내에 보행(locomotion)을 익히나, 파쿠르는 훨씬 어렵고 수년간의 연습이 필요
- elevation mapping으로 환경을 인식하고, RL로 Policy를 학습한 사례 - https://arxiv.org/pdf/2209.12827
- 최근 연구 동향
- task-specific policies를 훈련하고, 상위 모듈로 이를 조합 (elevation map 사용)
- end-to-end depth image 사용 - https://arxiv.org/abs/2309.05665
- 일반적 장애물 형상에 대한 일반화 부족 (형태, 길이, 높이, 로봇과 장애물간의 거리)
- 논문만의 차별점
- 간단한 개념으로 더 extreme parkour를 구현
- privileged information을 통해 scan dots을 사용 -> 지형 형상 전반에 일반화
- 정책이 스스로 방향(heading)을 결정하도록 함 -> 경사로 점프(tilted ramps)와 같은 난이도 높은 동작 가능
- 통합 보상 설계 (Genearl-purpose reward principle) 사용
- A1 로봇 기준, 최대 1.5배 높이, 1.5배 거리 점프 -> 최대 높이 2배, 최대 점프 2배 가능
3. Method
- 논문의 목표
- 단일 신경망에서 훈련을 진행하여, 센서 정보(뎁스이미지)를 엔드 투 엔드로 로봇 동작을 연결하는 정책을 학습하고자 함.
- input : 로봇의 온보드 depth camera & onboard sensing
- output : 관절 각도 명령 joint-angle-coomands
- 최근 연구 동향
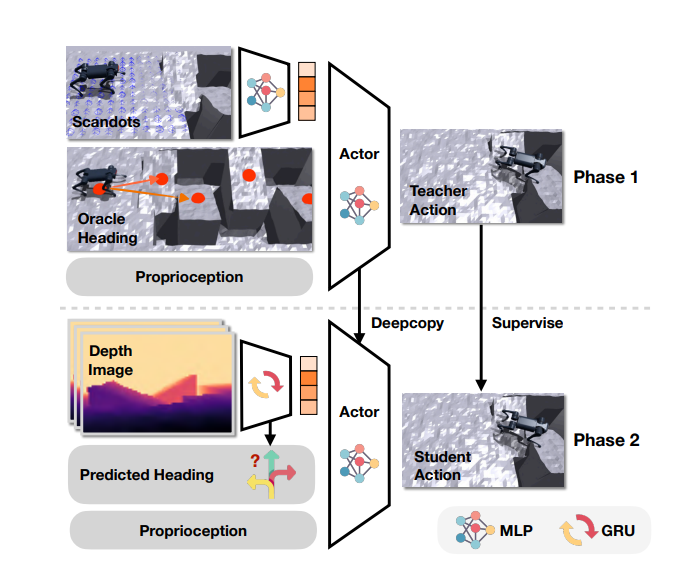
- adaptive motor policies 학습을 위해, student-teacher training을 사용
- 1단계 : privileged information이 포함된 teacher가 policy를 학습
- 2단계 : teacher policy를 바탕으로 온보드 센서만 사용하는 student로 distill
- ROA(Regularized Online Adaptation) 기법이 등장하여 adaptaion phase(적응 과정)을 single phase(단일 단계로) 통합
- Vision Backbone 학습
- teacher policy : privileged scandots information를 활용해 학습
- student policy : depth 이미지만 활용하도록 teacher policy를 distill
- 해당 논문에서는 두 단계 학습 과정을 사용
- 1단계 : Privileged Information를 이용한 RL 학습
- 단순하면서 통합적인 보상 공식을 제시하여, 다양한 동작들이 자동적으로 나타나고 지형 형태에 완벽하게 적응하도록 함.
- 2단계 : 파쿠르 수행 중, 로봇은 스스로 방향은 결정
- 적절히 배치된 waypoints를 사용하여 방향을 제공하고, 뎁스 정보에서 이러한 방향(oracle heading directions)을 예측
3.1 Unifeid Reward for Extreme Parkour
- 파쿠르에서는 로봇이 임의의 방향 명령(direction commands)를 따르는 방식이 아니라, 최적의 방향(optimal direction)을 스스로 선택한 자유가 필요하다
- 방향 결정 방식 : 지형 위에 waypoints를 배치하고 이를 기반으로 방향을 계산하는 방식을 사용
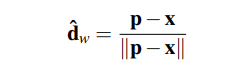
- p : 다음 웨이포인트 위치
- x : 로봇의 현재 위치
- d^w : 로봇이 향해야할 방향 단위 벡터 -> 로봇 위치 x에서 웨이포인트 p로 향하는 방향을 나타냄
- 속도 추적 보상 (velocity tracking reward)
- 로봇이 계산한 방향 d^w에 따라 목표 속도 v_cmd를 맞추도록 속도 추적 보상을 설계
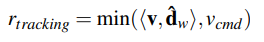
- v ∈ R 2 : 월드 좌표계 기준 / vcmd ∈ R : 목표 속도
- 기존 연구에서는 base frame에서 속도를 추적했으나, 본 논문에서는 월드 좌표꼐에서 속도를 추적함
- 로봇이 보상을 악용 (obstacle에서 주변을 빙글빙글 도는) 의도치 않은 행동을 학습하는 것을 방지하기 위함
- 가장 자리 접촉 페널티 (Clearance Penalty)
- 로봇이 장애물 가장자리 (edge)에 너무 가깝게 발을 디디는 위험한 행동을 함 -> 에너지 소비를 최소화하려는 경향
- 이는 매우 위험하므로, 패널티를 부여
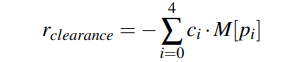
- i = 0, 1, 2, 3, 4 : 각 다리에 대한 인덱스 (로봇은 사족보행 로봇)
- ci : 해당 다리 i가 땅에 닿으면 1, 아니면 0
- M[pi] : 다리 위치 pi가 장애물 가장자리(edge) 5cm이내에 있으면 1, 아니면 0
- 스타일 동작 유도 보상 (Stylized Motion Reward)
- 파쿠르 동작의 중요한 특징은 다양한 스타일, 시각적으로 멋진 동작(aesthetically pleasing style)을 수행해야함
- 다양한 동작 스타일(explore diverse styles)을 유도하기 위해 임의의 목표 방향을 따르도록 추가 보상 항목 설계
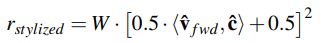
- vˆ f wd : 로봇 몸체가 향하는 전방
- c : 원하는 방향 / cˆ = [0,0,−1] T 진행 시, 손으로 서기 훈련 가능
- W : 보상 활성화 여부를 결정하는 스위치 (훈련 중에는 0 or 1 무작위, 실제 배포 시는 사람이 제어)
- 추가적으로 정규화 항목(regularization terms) 사용
3.2 Reinforcement Learnigng form Scandots (Phase1)
- 스캔닷을 활용한 강화학습 : 앞서 설명한 보상들을 사용해, 시뮬레이션 환경에서 model-free RL로 policy를 학습
- Policy Inputs
- proprioception x : 로봇 자체 상태 정보
- scandots m : 특권 시각 정보(privileged visual information)이며 장애물을 점 형태로 표현한 데이터 / 시뮬레이션 특권 정보
- target heading dˆ : 로봇이 가야할 방향에 대한 단위 벡터
- walking flag W : 특정 동작 수행 여부 제어 변수
- commanded spped v_cmd : 목표 이동 속도
- ROA (Regularzied Online Adaptation) 활용
- ROA : 환경 특성을 추정하는 적응 모듈을 학습하는 기법
- 적응 모듈은 관측값의 과거 기록을 활용해 환경 상태를 추정하도록 훈련
- 로봇이 실시간으로 환경 변화에 적응할 수 있도록 돕는 역할
- 파쿠르 기술 학습을 위한, 다양한 지형을 시뮬레이션 상에서 제작
- Tilted ramps (기울어진 경사로), gaps (틈), hurdles(허들), high step terrains(높은 계단)
- Automatic Diffculty Adjustment (난이도 자동 조절) 방식 사용
- 난이도가 점진적으로 상승하는 방식을 적용
- 1단계 : 로봇 초기 상태 초기화 -> 쉬운 단계에서 시작
- 2단계 : 난이도 상승 -> 에피소드 진행 중 지형의 절반 이상 통과하면 어려운 난이도로 승급
- 3단계 : 기대한 거리의 절반도 이동하지 못하면 쉬운 난이도로 강등
3.3 Distilling Direction and Exteroception (Phase 2)
- 방향과 외부 감각의 융합 학습 진행
- Phase1의 정책의 한계 : 실제 로봇에 바로 적용하기 어려움
- 시뮬레이션에서는 candots이라는 특권 시각 정보 사용 / 실제 로봇에서는 전방 카메라에서 촬영한 depth 만 사용 가능
- Heading Direction 차이 : 시뮬레이션에서는 expert가 waypoints와 target directions을 명시적으로 제공
- 실제 로봇에서는 눈에 보이는 지형만 보고 스스로 방향을 추론해야함
- Phase2에서는 실제 적용 가능한 정책으로 만들기 위해, supervised learning 사용
- CNN + GRU 기반 파이프라인 설계
- CNN : 뎁스 이미지를 feature extraction
- GRU : 시간에 따른 과거 상태를 기억해 활용
- DAgger (Data Aggregation)를 사용해 정책을 훈련
- teacher : Phase 1 정책
- student : Phase 2 정책
- Phase2의 정책 초기값으로 Phase 1 정책을 copy해서 사용
- 방향(Heading) 예측의 어려움
- 뎁스 이미지로 부터 방향을 예측하는 네트워크는 Phase 1에서 pre-training이 되어 있지 않음 -> 그대로 사용하면 성능 저하
- MTS(Mixture of Teacher and Student) 교사 - 학생 혼합 방법을 제안
- 학생이 관측하는 방향 명령 obsθ 정의
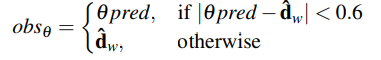
- obs_pred : 학생이 예측한 방향
- dˆw : Teacher가 제공하는 웨이포인트 기반 목표 방향
- 0.6 이상이면, 학생이 예측 사용 / 미만이면 교사 방향 사용
4. Result
4.1 Experimental Setup
- Unitree A1 로봇 (12개 관절을 가진 사족보행 로봇 사용)
- 허벅지 관절 높이 : 26cm
- 몸체 길이 : 40cm
- depth camera : Intel RealSense D435 ( 8 hz ~ 12hz)
- depth image preprocessing : 좌측에 발생하는 dead pixels를 잘라내고, 58 x 87 기반으로 다운 샘플링
- depth image latency 보정 : 지연 방지를 위해, 고정 지연 0.08초를 적용
- tp 측정 : 뎁스 이미지 수신 -> latent 생성 -> 전송 직전까지 걸린 시간(tp) 기록
- 지연 보정 : tp < 0.08초이면 0.08 - tp 만큼 대기 이후 latnet 전송 / tp > 0.08이면 즉시 전송
- Jetson Xavier NV
- depth backbone : 10hz
- 기본 정책 생성 : 50hz
- 통신 방식 : UDP 프로토콜 사용
- Proprioception 지연 고정 : 로봇 상태 정보 수집 및 처리 과정에서도 고정 지연 0.016초 적용
- 훈련 시간 : RTX 3090 GPU 1개로 20시간 이내 학습 가능
4.2 Emergent result (자발적으로 나타난 행동 결과)
- 단순한 보상함수는 사전 지식(prior knowledge)는 거의 반영하지 않고, 로봇이 자유롭게 스스로 행동을 학습하도록 함
- 높이 뛰어오르기 : 0.5m 높이의 박스 위로 뛰어오름
- 장애물에 가까워질 때 보폭을 줄임, 앞다리와 뒷다리를 장애물에서 적절한 거리로 맞춤
- 점프 순간, 뒷다리를 강한 토크와 높은 속도로 뻗어 몸을위쪼으로 밀어 올림, 동시에 앞다리를 장애물 위쪽으로 넘김
- 앞다리가 장애물 위에 닿으면, 그것을 이용해 몸을 위로 끌어올리고, 뒷다리를 몸 가까이 붙여 장애물을 넘어감
- 이후 네발 보행으로 돌아감
- 멀리 뛰기 : 0.8m 폭의 틈을 뛰어넘음
- 앞발을 틈 가장자리에 맞춰 정렬 후, 뒷발도 가장자리에 가깝게 가져와 점프 거리를 최대로 확보
- 점프 순간, 뒷발을 뒤로 차서 몸을 앞으로 밀어내고 동시에 위로 튀어오름, 앞발을 미리 뻗어 반대편 착지를 준비
- 비행 중 동작 : 공중에 있는 동안, 뒷발도 뻗어 힘 전달 시간을 극대화
- 이후, 앞발을 먼저 내리고, 뒷발을 그쪽으로 끌어와 안전하게 착지, 착지 후 보행 자세로 돌아감
- 손으로 서기 : 4발 보행에서 2발 보행으로 자연스럽게 전환
- 몸을 앞으로 숙이면서, 앞발에 체중을 싣음, 뒷발을 위로 차올려서 몸을 수직으로 만듬
- 수직 자세가 되면, 뒷발은 중립 상태로 두고, 작은 조정으로 균형을 유지
4.3 Comparison to Baselines
- 제안한 시스템의 각 구성 요소가 실제로 성능에 기여하는지 검증하기 위해, 두가지 종류의 기준 실험 설계
- 첫 번째 세트 : 보상 설계와 전체 시스템 평가
- Noisy : depth + odom을 융합해 elevation map을 생성해 사용하는 시스템을 묘사하여 엔드투 엔드와 비교
센서 노이즈를 추가하여 Phase1 정책을 훈련
- No inner product reward : 내적 보상 대신, 속도 추적 방식 사용 -> 내적 보상 설계가 필요한지 검증
- No feet clearance penalty : 발 위치 페널티 제거 -> 실제 안정성에 중요한지 검증
- 두 번째 세트 : 방향 및 정책 증류 평가
- heading과 distillation 이 필요한지 확인하고자 설계
- Both : student가 항상 자신이 예측한 heading을 관측하도록 설정
- Mask : heading observation을 0으로 마스킹, action만을 모방하도록 학습
- Oracle : student가 항상 waypoint 기반 teacher의 정확한 eading을 관측하도록 설계 -> 이론상 최고 성능을 확인
- 시뮬레이션 결과 -> 해당 논문의 방법론이 최고의 성능을 보임
- 지형 : 경사로, 계단, 틈, 허들 -> 난이도 증가 순서대로 배치한 장애물 코스 제작
- 256개의 로봇을 동시에 시작시켜 다음 두가지 지표를 측정
- 평균 x 방향 이동 거리 (MVD) : 로봇이 넘어지기 전까지 전진한 거리 (클수록 좋음)
- 평균 모서리 접촉 빈도 (MEV) : 로봇 발이 모서리에 접촉한 횟수 (낮을 수록 좋음)
- 실제 환경 결과 -> 해당 논문의 방법론이 최고의 성능을 보임
- NoClear와 NoDir 실제 환경을 비교
5. Discussion
- 논문에서 제안한 방법이 시뮬레이션, 실제 환경 모두 가장 좋은 성능을 보임
- 통합 보상(Inner Product Reward), 발 위치 패널티(Feet Clearance Penalty), 방향 예측 종류(MTS) 등 제안 기법들이 성능 향상에 모두 기여했음을 확인